How to scale an SPA?
Amsterdam JS 2018 · Amsterdam, Netherlands
by Asim Hussain · 31 May 2018
I knew how to build a single-page app — what students kept asking was what to do with it once it was built. So at Amsterdam JS I took my own little Trump-tweet-driven stock-trading bot as a running example and walked through how I’d actually architect and scale a modern web app on the cloud, without reaching for the platform everyone reaches for by reflex.
AI-generated summary of my talk
Jump into the talk
- 0:00 The Trump-tweet trading bot
- 3:08 What this talk is really about
- 7:11 On-premise to IaaS to PaaS
- 8:11 What's an SPA, and where do you host it?
- 10:16 Static vs dynamic — and a quiz
- 14:22 Why static matters: caching
- 17:22 Serve from storage, not a server
- 20:26 Serverless, and why storage counts
- 23:28 The API on Functions-as-a-Service
- 26:34 Durable Functions for the long-running engine
The bot, and the real question
I opened with a confession: I once bought a Bitcoin in 2013, held it as it soared — and then sold half the same day and the rest four days later. So while some people might call me the Asian Warren Buffett, the truth is even I could do with help investing. Planet Money once built a bot that traded stocks off Donald Trump’s tweets — he’d tweet about a company, the share price would move — but they shut it down, because they’re a podcast, not an investment firm. So I built my own. It’s made me about sixty-one dollars this year, roughly fifty cents an hour of effort, and I’m calling that a win.
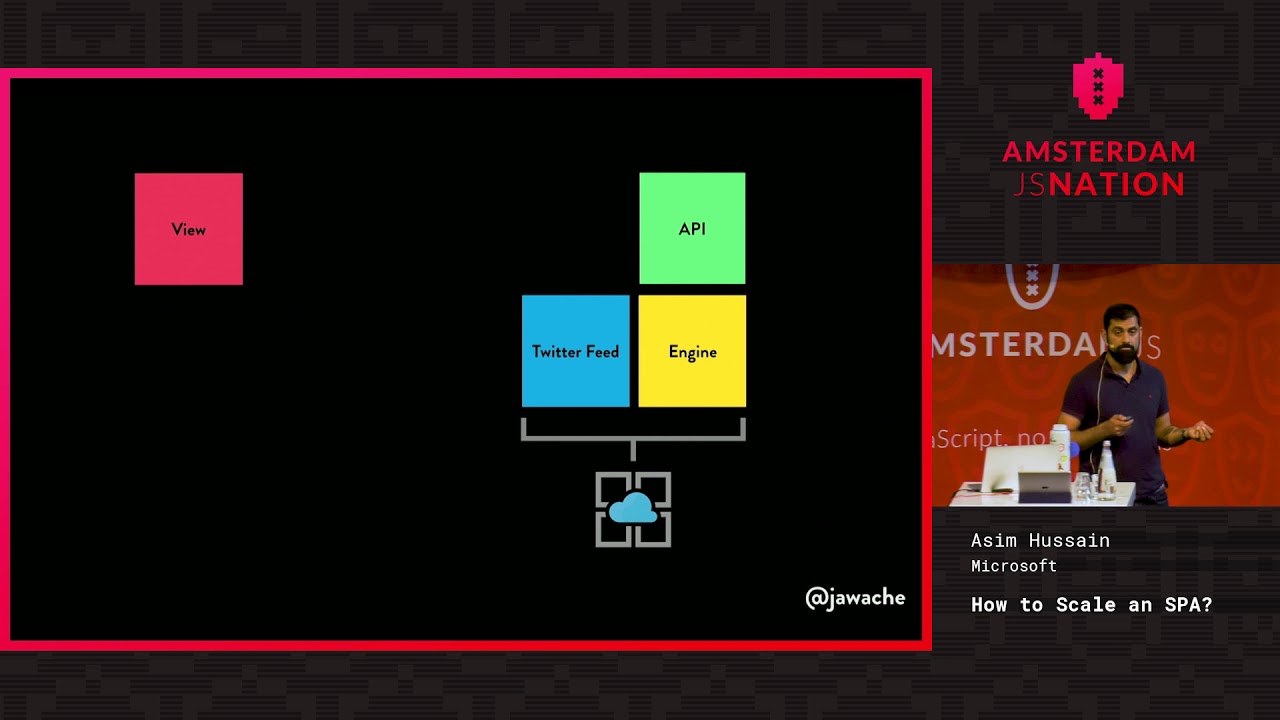
The secret sauce of the bot itself stays with me. This talk is about something more useful: how to architect and scale an app like it. I picked the bot because it has some meat — a Twitter feed listening for tweets, and a proper trading engine that has to be robust. Not long ago this was easy: a Node/Express app, server-side rendered, you knew where everything went and you’d deploy the whole atomic thing onto a server. Things have changed.
On-premise, to IaaS, to PaaS
Quick tour of how we got here, because this is really a cloud-deployment talk. We started on-premise: you bought your own hardware, and if a hard drive failed it was your problem to fix. Then came infrastructure as a service — someone else owns the hardware in a data centre, you rent it via virtualisation, but you still own the operating system and the framework. Then platform as a service — they own the hardware and the OS, and you just install your framework of choice. App Services, Google App Engine, Amazon Beanstalk, and most famously Heroku — those are all PaaS. That’s where I used to host everything, and that’s exactly the habit I want to break.
An SPA is static — that’s the whole trick
Today I’d rip the view layer out and build the front end as a single-page app: an application where only one page is ever returned from the server. Run ng build in Angular and you get an output folder — whether your app has one URL or ten thousand, it’s just a folder of files with a single index.html. That file loads the JavaScript and CSS, the JavaScript bootstraps, and it takes over navigation from there.
So where do you put it? The mistake I see constantly is people dropping it onto a PaaS, maybe a Node server in front serving it as a static asset, because that’s the platform they always used. So I run a quiz on static versus dynamic. A static request returns the same data for the same URL no matter who asks or when; a dynamic one returns different data to different users. Is an SPA static or dynamic? It’s static. All I showed you was a folder, and the contents of that folder don’t change for any user, at any time — until you recompile it. Once it’s up, it’s static.
Static unlocks caching — and caching saves money
Why does that matter? Caching, which is the single most important thing for web performance. A request crosses several nodes that can each cache, and people forget two of the three. Everyone knows browser caching, and most know CDNs — though if you’ve got a CDN you’re paying for it. The interesting one is proxies: ISPs in regions with poorer internet infrastructure run their own proxy caches to avoid upstream costs, and if your request hits one it never touches your CDN or your servers. From the browser tab it looks like a full request went out — but the proxy served it, and you paid nothing.
You unlock this with headers. The one that matters is cache-control, and the value that matters is public — and you can only use it because your content is static and identical for everyone. That tells every node in the chain it’s safe to store. For HTML I’d cache it for just five minutes, because there’s nothing worse than HTML pinned for ten years that no one can ever update — five minutes still soaks up a load spike.
The second reason to be static is serving. A dynamic server like Node is great at returning different data per request, but for static assets you want a service purpose-built for it: Azure Storage, or its most famous equivalent, Amazon S3. The code underneath is dead simple — read a file off disk, stream it back — and there are huge low-level optimisations for exactly that. I showed an Apache Bench demo hammering 10,000 requests at the same content served from a PaaS App Service versus from storage, and storage wins: faster, much cheaper, and I didn’t have to tweak or scale a thing — the servers underneath storage are auto-scaling for me.
Storage is serverless — so make everything serverless
Here’s the move that ties it together. Serverless means someone else does the scaling and you pay only for actual usage, not predicted usage. I still remember senior management asking me to forecast next year’s load so we could buy enough servers for the peak — an impossible guess, and you end up paying for capacity you don’t need. Serverless kills that. And by that definition, storage is serverless — it quacks like a duck. It auto-scales, you pay only for bandwidth and storage. So if the front end is already on serverless storage, why not make the rest serverless too? SPA and serverless are a perfect conjoining of technologies.
So I’d put the API on Functions-as-a-Service — Azure Functions, AWS Lambda, IBM OpenWhisk. You stop hosting a web framework and just host a function that runs when a URL is hit. It’s billed per gigabyte-second plus executions, so zero calls is zero cost, and it auto-scales. The catch: a five-minute runtime cap, and it’s stateless.
That’s a problem for the Twitter feed and the trading engine, which are long-running — and I don’t want my engine switching off mid-trade. The mistake people make is putting that piece back on a PaaS just because it’s long-running. Instead you need orchestration. Your browser already orchestrates your API calls — it holds the state, decides to retry a failed request — and we need the same for the engine. Azure’s answer is Durable Functions (AWS’s nearest cousin is Step Functions). They have a lovely generator syntax: you yield a request, and the Durable framework checkpoints the function’s state to disk and drops it out of memory. A second yield could return in two days and the function simply reappears and continues from where it left off — a function that outlives the five-minute cap. So the whole thing becomes: a static SPA on storage, an API on Functions-as-a-Service, and the long-running work orchestrated by Durable Functions. All serverless, because we love serverless.